这篇文章的标题表明研究的主题是用户级超短期负荷预测,并且该预测方法基于多尺度分量特征学习。让我们逐步解读这个标题:
-
用户级: 这表示研究的焦点是在个体用户层面上进行的。负荷预测可能是指电力系统中的负荷,即电力需求。用户级的负荷预测意味着研究者可能正在关注个别用户的电力使用情况,而不是整个系统的平均值。
-
超短期: 这表示研究关注的是非常短的时间范围内的负荷预测,而不是中长期的预测。在电力系统中,超短期通常指的是未来几分钟或几小时内的时间跨度。
-
负荷预测: 这是研究的目标,即通过某种方法来预测电力负荷,以便更好地规划和管理电力系统。
-
基于多尺度: 这表示在进行负荷预测时,采用了多个尺度(或者说多个层次)的信息。这可能包括从不同时间尺度或空间尺度上获取的数据或特征。这种多尺度的方法可以提供更全面、更准确的信息,有助于更精细地捕捉负荷变化的特征。
-
分量特征学习: 这表明在预测模型中,研究者采用了学习分量特征的方法。这可能涉及到使用机器学习或深度学习技术,以自动地从数据中学习和提取与负荷变化相关的特征。
因此,总体来说,这篇文章的研究关注在用户级别上,通过基于多尺度分量特征学习的方法,对超短期内的电力负荷进行预测。这种方法的目标可能是提高负荷预测的准确性和适用性,从而更有效地管理电力系统。
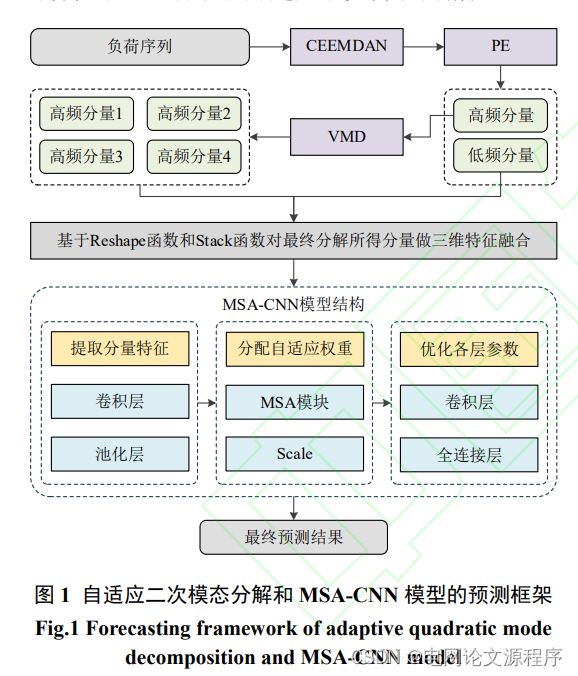
摘要:针对用户级负荷波动性强,一步分解后数据维度增加导致运行效率降低以及精度提升有限等问题,提出一种新的多尺度分量特征学习框架,用于用户级超短期负荷预测。构建基于自适应噪声的完整经验模态分解(complete ensemble empirical mode decomposition with adaptive noise,CEEMDAN)、排列熵(permutation entropy,PE)以及变分模态分解(variational mode decomposition,VMD)的自适应二次模态分解框架,捕捉周期性等时序特征,并降低其非平稳特性;采用多维特征融合的方式挖掘各本征模态函数之间的耦合关系,丰富特征信息;利用改进的多尺度空间注意力(multiscale spatial attention,MSA)模块沿时间、空间以及通道等多尺度提取时空特征及多分量间耦合关系,进而便于卷积神经网络(convolutional neural network,CNN)学习多分量特征。基于江苏省南京市房地产业、教育业以及商务服务业共12位用户的实际负荷数据进行算例分析,各行业平均绝对百分误差分别为5.82%、4.54%以及8.78%,与效果最好的对照模型相比,分别降低了10.46%、6%以及7.48%,验证了该文模型具有较高的预测精度和良好的泛化性能。
这段摘要描述了一种针对用户级负荷波动性强、数据维度增加导致效率降低以及精度提升有限等问题的新型负荷预测方法。以下是对摘要中各部分的解读:
-
问题描述:
- 用户级负荷波动性强: 用户级负荷变化大,可能由于个体用户的不同用电行为导致波动性增加。
- 一步分解后数据维度增加: 一般的分解方法导致数据维度急剧增加,可能影响运行效率。
- 运行效率降低以及精度提升有限: 由于上述问题,预测模型的运行效率下降,而预测精度提升有限。
-
提出的方法:
- 多尺度分量特征学习框架: 为应对上述问题,提出了一种多尺度分量特征学习框架,旨在更有效地处理用户级超短期负荷预测。
- 自适应二次模态分解框架: 使用自适应噪声的完整经验模态分解(CEEMDAN)、排列熵(PE)、以及变分模态分解(VMD)构建自适应二次模态分解框架,用于捕捉周期性等时序特征,并降低非平稳特性。
- 多维特征融合: 采用多维特征融合的方式挖掘本征模态函数之间的耦合关系,以丰富特征信息。
- 多尺度空间注意力模块: 引入改进的多尺度空间注意力模块(MSA),沿时间、空间、通道等多尺度提取时空特征及多分量间耦合关系。
- 卷积神经网络(CNN)的学习: 利用上述处理后的特征,便于卷积神经网络(CNN)学习多分量特征。
-
实验结果:
- 实验数据: 使用江苏省南京市房地产业、教育业以及商务服务业的12位用户的实际负荷数据进行算例分析。
- 预测性能: 在不同行业中,该方法的平均绝对百分误差分别为5.82%、4.54%和8.78%。
- 与对照模型比较: 与效果最好的对照模型相比,分别降低了10.46%、6%和7.48%。这表明该文提出的模型在预测精度和泛化性能方面具有较高的水平。
综合而言,这个方法通过引入自适应二次模态分解、多尺度空间注意力模块以及多尺度特征学习等手段,成功地应对了用户级负荷预测中的挑战,并在实验证明了其在不同行业中的优越性。
关键词:负荷预测; 卷积神经网络;自适应二次模态分解;多尺度空间注意力机制;
这组关键词涉及到负荷预测领域中的一些关键概念和技术手段。下面对每个关键词进行解读:
-
负荷预测: 这是研究的核心目标,指的是对未来一定时间内电力系统的负荷进行预测。这对于电力系统的规划和运营非常重要,因为准确的负荷预测可以帮助决策者更好地安排发电和电力配送。
-
卷积神经网络 (CNN): 这是一种深度学习模型,特别适用于处理网格结构的数据,如图像。在负荷预测中,CNN可能被用于学习数据中的时空特征,帮助提高预测的准确性。CNN的卷积层可以有效地捕捉输入数据的局部模式。
-
自适应二次模态分解: 这可能是一种信号处理的技术,用于对负荷数据进行分解。二次模态分解是一种数学工具,可以将信号分解为多个成分,而自适应表示这个过程可能根据数据的特性进行调整,以更好地适应不同的负荷模式。
-
多尺度空间注意力机制: 这涉及到在不同空间尺度上引入注意力机制,以便更有效地捕捉数据中的关键信息。多尺度表示在分析中考虑不同的空间范围,而注意力机制则允许模型更加关注输入中重要的部分。这对于负荷预测而言,可以帮助模型更好地理解和利用不同尺度上的变化。
综合而言,这些关键词表明在负荷预测中,研究者可能采用了卷积神经网络这一深度学习模型,结合自适应二次模态分解和多尺度空间注意力机制等技术手段,以提高对电力负荷行为的建模和预测能力。这些方法的结合可能有助于更全面、更准确地捕捉电力系统中复杂的负荷模式。
仿真算例:本算例的数据来源为江苏南京某用户的实际负荷数据,采样时间为 2017 年 8 月 1 日至 2018 年7 月 31 日,采样间隔 1 小时,共计 8760 条数据。考虑到负荷通常具有“日周期性”等周期性特征以及“夏、冬负荷高,春、秋负荷低”等季节性特征,而该数据集中包含了各种季节以及不同天气情况下的数据,因此认为本文所选数据集具备较强的实用性。将数据集按照 8:2 的比例分为训练集和测试集。在此基础上,为验证自适应二次模态分解对模型性能的影响,分别分析自适应二次模态分解后负荷曲线的变化以及采用 CEEMDAN 一步分解、VMD-CEEMDAN 两步分解以及自适应二次模态分解时模型的预测性能;为验证所提 MSA 模块对模型性能的影响,对比分析了不使用 MSA 模块、使用 SE 模块以及使用 MSA 模块这三种情况下模型的性能;最后,将本文所提模型与 1DCNN、LSTM、1DCNN-LSTM 以及 TCN 等模型做对比,从预测性能和运行时间两个方面验证了本文模型的可靠性。
仿真程序复现思路:
复现本文仿真的思路主要包括以下几个步骤:
-
数据加载与预处理:
- 从给定的数据源中加载实际负荷数据。
- 进行时间序列的处理,确保时间信息被正确解析。
- 将数据集按照 8:2 的比例划分为训练集和测试集。
-
自适应二次模态分解(CEEMDAN)对模型性能的影响验证:
- 对训练集的负荷数据进行自适应二次模态分解。
- 分析不同分解方式(CEEMDAN 一步分解、VMD-CEEMDAN 两步分解、自适应二次模态分解)对负荷曲线的影响。
- 在每种分解方式下,使用相应的特征进行模型训练,并评估预测性能。
-
多尺度空间注意力模块(MSA)对模型性能的影响验证:
- 对比分析三种情况下的模型性能:不使用 MSA 模块、使用 SE 模块、使用 MSA 模块。
- 分别应用这些模块,训练模型,并评估其在测试集上的性能。
-
模型比较与验证:
- 构建本文提出的多尺度分量特征学习框架,并与其他模型(1DCNN、LSTM、1DCNN-LSTM、TCN等)进行对比。
- 在每个模型上使用训练集进行训练,并在测试集上进行性能评估。
- 比较各模型在预测性能和运行时间方面的表现。
下面是一个简化的伪代码表示,实际实现可能需要根据具体情况进行调整:
import numpy as np
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_squared_error
from sklearn.preprocessing import StandardScaler
from your_model_module import CustomModel # 自定义模型的导入
# 步骤1:数据加载与预处理
def load_data(file_path):
data = pd.read_csv(file_path) # 假设数据存储在CSV文件中
return data
def split_data(data, ratio=0.8):
train_data, test_data = train_test_split(data, test_size=1-ratio, shuffle=False)
return train_data, test_data
# 步骤2:自适应二次模态分解对模型性能的影响验证
def apply_ceemdan(data):
# 在这里实现CEEMDAN或其他所需的分解方法
# 返回分解后的特征
features = perform_ceemdan(data)
return features
# 步骤3:多尺度空间注意力模块对模型性能的影响验证
def apply_msa(data, use_msa=True):
# 在这里实现多尺度空间注意力模块或其他所需的模块
if use_msa:
data = msa(data)
return data
# 步骤4:模型比较与验证
def train_and_evaluate_model(train_features, test_features, labels):
model = CustomModel() # 使用你自定义的模型
model.fit(train_features, labels)
# 在测试集上进行预测
predictions = model.predict(test_features)
# 评估模型性能
mse = mean_squared_error(labels, predictions)
print(f"Mean Squared Error: {mse}")
if __name__ == "__main__":
# 步骤1:数据加载与预处理
data = load_data('load_data.csv')
train_data, test_data = split_data(data, ratio=0.8)
# 步骤2:自适应二次模态分解对模型性能的影响验证
ceemdan_train_features = apply_ceemdan(train_data)
ceemdan_test_features = apply_ceemdan(test_data)
# 步骤3:多尺度空间注意力模块对模型性能的影响验证
msa_train_features = apply_msa(ceemdan_train_features)
msa_test_features = apply_msa(ceemdan_test_features)
# 步骤4:模型比较与验证
labels = train_data['target_column'] # 假设目标列为 'target_column'
train_and_evaluate_model(msa_train_features, msa_test_features, labels)
在这个伪代码中,需要根据具体情况填充缺失的部分,特别是在实现CEEMDAN、MSA模块和自定义模型的部分。确保模型能够正确地处理输入数据,训练和预测,并且在最后的评估步骤中,可以选择更多的性能指标来评估你的模型。





